
Check spelling at the command line
I like to write a lot of articles about Linux, FreeDOS, programming, and open source software. I am pretty confident of my spelling and grammar, but sometimes it’s nice to run a quick spell-check to see if I have any spelling errors in my document. When I write documents in LibreOffice, I can use the spell-checker that’s built into LibreOffice, or I can rely on the “red squiggle underline” to catch spelling errors as I type.
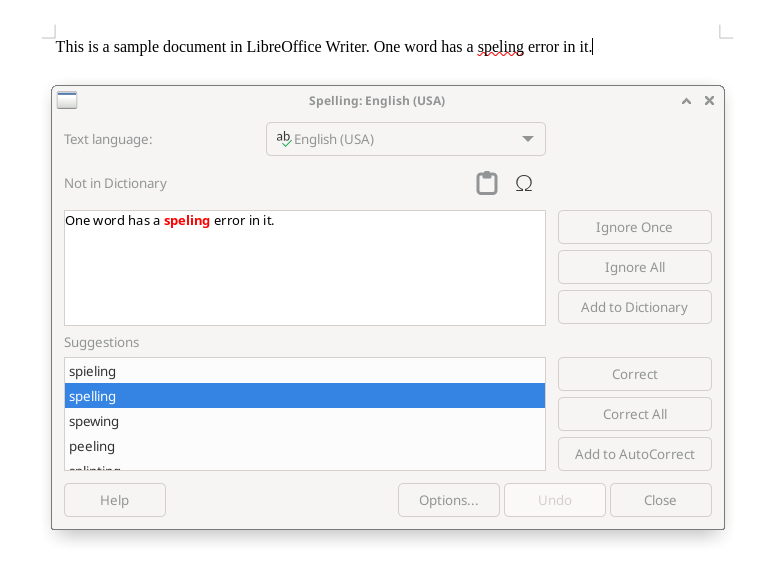
But I write most of my articles in Markdown. If I’m using Vim, I can turn on the automatic inline spell-checker using this Vim command:
:set spell spelllang=en_usAnd that does a great job of catching spelling errors as I type. But I prefer to type without distraction, and capture my thoughts quickly. Going back to fix typos while I type is very distracting for me. Instead, I wanted to have a command line tool where I could run a quick command to check for any spelling errors in my document after I’d finished writing it.
Original spell-checkers
The original Unix introduced the typo command in Unix 3rd Edition. The spell command was added in its place starting with Unix 6th Edition. Each command does basically the same thing: checks every word in a document, and prints a sorted list of unique misspelled words.
As an undergraduate, our campus lab of Sun computers had ispell, which was an interactive version of spell that showed any misspelled words in context in the text document, and suggested correct spellings. These days, GNU Aspell replaces ispell for checking spelling at the command line on Linux and other Unix-like systems.
Building your own spell-checker
You can build your own version of the original typo command using a few Linux commands. At a high level, you can do this by breaking apart a document into words, sorting that list of words and removing duplicates, then comparing that list to a list of correctly spelled words.
It’s easiest to convert all words to lowercase, and that’s how the original typo command worked. To convert all text to lowercase, use the tr (transliterate) command, replacing all uppercase letters with lowercase letters:
tr 'A-Z' 'a-z'Next, remove all punctuation from the input. You can also use tr to do this, with the -d (delete) option:
tr -d '.,:;"?!@()'Then, break up the text so that each word appears on its own line. A simple way to do this is with the tr command, and convert spaces to newlines:
tr ' ' '\n'From there, you can use sort to sort the list, and uniq to remove any duplicates:
sort | uniqThe last step uses the comm (common lines) command to compare two files: the list of words from the document with another list of correctly spelled words. The comm program assumes both lists are sorted in the same way, and it produces output where the lines unique to the first file are in one column, lines unique to the second fiel are in a second column, and the lines common to both appear in a third column.
When comparing lists of words, that means the correctly spelled words (words that appear in both the document and the list of correctly spelled words) will be in column 3, while misspelled words (words that appear only in the document) will be in column 1. To display only column 1 (misspelled words) we need to disable columns 2 and 3 with the -2 and -3 options:
comm -2 -3 - $wordsTo put that all together, the full command line looks like this:
cat "$@" | tr 'A-Z' 'a-z' | tr -d '.,:;"?!@()' | tr ' ' '\n' | sort | uniq | comm -2 -3 - $wordsThis requires a sorted list of correctly spelled words. Every Unix-like system should have this list saved as /usr/share/dict/words, but the list may not be sorted in the same way that the sort command would generate, so I like to work with a local copy. My full typo script looks like this:
#!/bin/bash
words=$HOME/lib/words.tmp
[ -f $words ] || sort /usr/share/dict/words > $words
cat "$@" | tr 'A-Z' 'a-z' | tr -d '.,:;"?!@()' | tr ' ' '\n' | sort | uniq | comm -2 -3 - $wordsLet’s test it! Let’s say I had this one-line document called test.md that had a single misspelled word:
This is a sample document with a mspelled word.If I run the typo script against this file, I get the one misspelled word as the only output:
$ typo test.md
mspelledA streamlined version
That typo script works well for me, but I’ve experimented with other ways to implement it. The basic steps remain the same, but I wanted to use the character class model from GNU tr to do the same thing. One way is to start is with the -c (complement) option to convert any character that is not a letter into a newline character:
tr -c '[:alpha:]' '\n'Then I wanted to immediately reduce the work for following steps by removing the blank lines. The grep command can do this easily:
grep -v '^$'The remaining steps are much as they were in the original. The script converts uppercase letters to lowercase letters, this time using the [:upper:] and [:lower:] character classes instead of A-Z and a-z:
tr '[:upper:]' '[:lower:]'Finally, sort the words with sort and remove duplicates with uniq before comparing the output with comm:
sort | uniq | comm -2 -3 - $wordsThe full command line looks like this:
cat "$@" | tr -c '[:alpha:]' '\n' | grep -v '^$' | \
tr '[:upper:]' '[:lower:]' | sort | uniq | comm -2 -3 - $wordsI followed the same basic steps to prepare the sorted list of correctly spelled words, based on the /usr/share/dict/words file. To accommodate any words that I use but aren’t in the system list, such as when I write about FreeDOS, I combine a list of my own words saved in mywords:
cat /usr/share/dict/words $HOME/lib/mywords | \
tr '[:upper:]' '[:lower:]' | sort | uniq > $wordsMy new typo script looks like this:
#!/bin/bash
words=$HOME/lib/words.tmp
if [ ! -f $words ] ; then
cat /usr/share/dict/words $HOME/lib/mywords | \
tr '[:upper:]' '[:lower:]' | sort | uniq > $words
fi
cat "$@" | tr -c '[:alpha:]' '\n' | grep -v '^$' | \
tr '[:upper:]' '[:lower:]' | sort | uniq | comm -2 -3 - $wordsThe script does mostly the same job as the previous typo script. For example, it finds the same misspelled word from the previous example:
$ typo test.md
mspelledThe limitation in this “improved” version is that the tr -c command removes hyphenation and apostrophes, so words like hadn't will get split up into hadn and t, resulting in hadn being identified as a “misspelled” word, despite the original word being listed in the correctly spelled words. However, as a quick spell-check tool, this works well enough for me.
More Stories
The Linux Philosophy for SysAdmins, Tenet 19—Backup everything frequently
Author’s note: This article is excerpted in part from chapter 21 of my book, The Linux Philosophy for SysAdmins, with...
Microsoft announces significant changes to Windows
In a sudden and short press conference early this morning, Microsoft has announced that Windows will be completely restructured at...
Open Source on macOS: Exploring Free Software on My M3 MacBook
Lead Image by Tom's Hardware Guide Open-source software is not restricted to Linux. While I spend most of my time...
Call for articles — Switching to Linux
October 14, 2025 is the last day of support for Win10 and over 400 million PCs can't upgrade to Win11....
Moving from Windows 10 to Linux
Instead of purchasing a new computer just to run a new version of Windows, consider installing Linux.
The Linux Philosophy for SysAdmins, Tenet 18—Document everything
“Real programmers don’t comment their code, if it was hard to write, it should be hard to understand and harder to modify.”
— unknown