
Converting WordStar files
The great thing about open source software is you can create your own tools. With a little programming knowledge, you can solve problems that are unique to you. And by sharing them under an open source license, others use your solution to tackle similar issues.
For example, I recently wanted to explore files created with WordStar. WordStar was a popular desktop word processor from the 1980s. It was originally published by MicroPro for the CP/M operating system, and later for MS-DOS where it gained the height of its popularity during the early 1980s.
WordStar is a very old file format, and not even LibreOffice Writer can import my WordStar 4.0 documents. But the WordStar file format is well documented, and I was able to create a tool to convert WordStar files to HTML. Here’s how I did it.
A brief look at WordStar files
WordStar used control codes for inline formatting such as bold and underlined text, and dot commands for other formatting such as margins and offsets.
The dot commands aren’t too far from nroff, the standard Unix document preparation system, although the WordStar commands are unrelated to each other. For example, while WordStar and nroff share a similar dot command to set the page length (.PL on WordStar, .pl on nroff) WordStar has unique dot commands to set features like the character width (.CW) or the footing (.FO) or the line height (.LH).
Inside the file, WordStar used single-byte 7-bit ASCII characters for printable characters. For example, the letter “capital A” (A) has the ASCII value of 65, or binary value 0100 0001, or hexadecimal 0x41.
WordStar used ASCII values below ASCII 0x20 (space) as control codes. To turn bold type on or off, WordStar inserted ASCII 0x02. Similarly, WordStar used ASCII 0x13 to turn underline on or off, and ASCII 0x19 to set and unset italic text. WordStar also supported other control codes for strikethrough, double strike, superscript, subscript, and other formatting.
White space characters were as you might expect: a space was a space, and a tab was a tab. Each line ended with the carriage return and new line pair (ASCII values 0x0d and 0x0a) which was the standard character pair for the DOS operating system. ASCII 0x1a marked the end of the file.
While WordStar used 7-bit ASCII characters for printable data, it reserved bit 8 (the “high bit”) to indicate characters that can be “microjustified” by the printer driver, such as to create adjusted paragraphs that go all the way to the right margin. To retrieve the printable value, the print driver would strip off the high bit. This feature was used through WordStar 4, but removed from later versions of WordStar, relying instead on the dot commands to control text justification.
A program to examine WordStar files
We can use this to examine a sample WordStar file, and convert it to HTML output. To demonstrate this program, I’ll use a sample file that contains just two paragraphs, using only bold and underlined text.
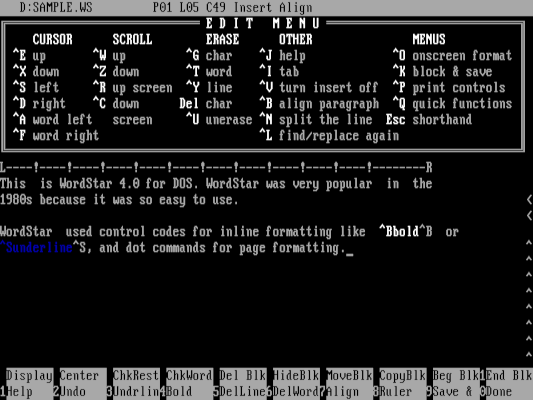
Defining the data
To create the program, we need to start with a few definitions. We’ll read data in a series of full 8-bit bytes. We’ll use a data type definition called BYTE that effectively creates an alias to the unsigned char data type, which is exactly 8 bits and holds unsigned values from 0 to 255.
typedef unsigned char BYTE;This program will read from a WordStar file and generate HTML output, using HTML tags like <b> to turn on bold and </b> to turn it off, and so on for other formatting. To control formatting, let’s define a data structure to indicate what text style is currently in effect. We can define our own data type called BOOL which can store either false (zero) or true (non-zero) values, and then create a structure with the different formatting that the program can recognize:
typedef enum { false, true } BOOL;
struct {
BOOL bold;
BOOL dblstrike;
BOOL underline;
BOOL superscr;
BOOL subscr;
BOOL strike;
BOOL italic;
} fmt;Displaying codes and characters
The main work of the program will be reading characters, recognizing which are control codes to control inline formatting, setting those values, and printing the text. We can define a function called show_codes that takes a single byte value, evaluates it, and takes action. While we might assume this program will generate output on the standard output, we can make the function a bit more flexible by also providing a file pointer for the output:
int show_codes(BYTE ch, FILE *out)
{
...
}Since the function just needs to work on one character value at a time, we can do everything inside a switch statement. This is effectively a “jump table” that performs an action depending on the value of the character. For this program, I’m not interested in micro justification, so I’ll write the function to use the lower 7 bits of the character:
#define FLIP(A) ( (A) ? false : true )
int show_codes(BYTE ch, FILE *out)
{
BYTE low;
low = ch & 0x7f;
switch (low) { /* ignore high bit */
/* a few formatting codes */
case 0x02: /* bold on/off */
fmt.bold = FLIP(fmt.bold);
if (fmt.bold) {
fputs("<b>", out);
}
else {
fputs("</b>", out);
}
break;
case 0x04: /* double strike on/off */
fmt.dblstrike = FLIP(fmt.dblstrike);
if (fmt.dblstrike) {
fputs("<bold>", out);
}
else {
fputs("</bold>", out);
}
break;
case 0x13: /* underline on/off */
fmt.underline = FLIP(fmt.underline);
if (fmt.underline) {
fputs("<u>", out);
}
else {
fputs("</u>", out);
}
break;
case 0x14: /* superscript on/off */
fmt.superscr = FLIP(fmt.superscr);
if (fmt.superscr) {
fputs("<sup>", out);
}
else {
fputs("</sup>", out);
}
break;
case 0x16: /* subscript on/off */
fmt.subscr = FLIP(fmt.subscr);
if (fmt.subscr) {
fputs("<sub>", out);
}
else {
fputs("</sub>", out);
}
break;
case 0x18: /* strikethrough on/off */
fmt.strike = FLIP(fmt.strike);
if (fmt.strike) {
fputs("<s>", out);
}
else {
fputs("</s>", out);
}
break;
case 0x19: /* italic on/off */
fmt.italic = FLIP(fmt.italic);
if (fmt.italic) {
fputs("<i>", out);
}
else {
fputs("</i>", out);
}
break;
/* printable codes */
case 0x09: /* tab */
fputs("<span>⇥</span>", out);
break;
case 0x0a: /* new line */
fputs("<span>↲</span><br>", out);
break;
case 0x0c: /* page feed */
fputs("<span>⇓</span>", out);
break;
case 0x0d: /* carr rtn */
fputs("<span>↩</span>", out);
break;
case 0x1a: /* eof */
fputs("<span>▪</span>", out);
return -1;
default:
if (low < ' ') { /* not printable */
fprintf(out, "<span>0x%X</span>", low);
}
else { /* printable */
fputc(low, out);
}
}
return 0;
}That’s a large switch statement that responds to different values. Taking a step back and looking at the switch statement at a high level, you might see that the block evaluates several kinds of characters: control codes that turn formatting on or off, printable codes like tabs and new lines, and printable characters.
The control codes that turn formatting on and off use a function called FLIP, which is actually a macro defined at the top. FLIP effectively flips the value of a boolean: if the input is true, it returns false; if it is false, it returns true. The formatting settings are stored in the global fmt structure.
The printable codes actually generate an HTML entity that visually represents the otherwise invisible whitespace. For example, tabs become a right arrow pointing to a vertical bar (⇥) and an end of file character becomes a small filled square (▪). Generating these whitespace entities inside <span>..</span> means we can format them later using CSS, either by setting them to a color such as color:pink or by removing them with display:none.
The main program
With this function to do the “heavy lifting” of the program, the rest is fairly straightforward. The main program will open a file, and process it using another function. The second function reads the file, and passes each byte value to the show_codes function.
void show_file(FILE *in, FILE *out)
{
BYTE str[100];
size_t len, i;
while (!feof(in)) {
len = fread(str, sizeof(BYTE), 100, in);
if (len > 0) {
for (i = 0; i < len; i++) {
if (show_codes(str[i], out) < 0) {
return;
}
}
}
}
}
int main(int argc, char **argv)
{
FILE *pfile;
/* check command line */
if (argc != 2) {
fputs("usage: wshtml {file}\n", stderr);
return 1;
}
/* init formatting */
fmt.bold = false;
fmt.dblstrike = false;
fmt.underline = false;
fmt.superscr = false;
fmt.subscr = false;
fmt.strike = false;
fmt.italic = false;
/* HTML start */
puts("<!DOCTYPE html>");
puts("<html><head><title>");
puts(argv[1]);
puts("</title><style>");
puts("span{color:pink;}");
puts("</style></head><body>");
/* process file */
pfile = fopen(argv[1], "rb");
if (pfile == NULL) {
fputs("cannot open file: ", stderr);
fputs(argv[1], stderr);
fputc('\n', stderr);
}
else {
show_file(pfile, stdout);
fclose(pfile);
}
/* HTML end */
puts("</body></html>");
return 0;
}Looking at the details, the main program also initializes the values for the fmt structure of formatting settings, and generates HTML file data around the body.
Putting it all together
Now all that’s left is to assemble the parts and run the program. This is how the program looks when it’s assembled, although I’ve left out the contents of the functions; you can copy them from the above.
#include <stdio.h>
typedef unsigned char BYTE;
typedef enum { false, true } BOOL;
struct {
BOOL bold;
BOOL dblstrike;
BOOL underline;
BOOL superscr;
BOOL subscr;
BOOL strike;
BOOL italic;
} fmt;
#define FLIP(A) ( (A) ? false : true )
int show_codes(BYTE ch, FILE *out)
{
...
}
void show_file(FILE *in, FILE *out)
{
...
}
int main(int argc, char **argv)
{
...
}Save this file as wshtml.c (“WordStar to HTML”) and compile it with this command:
$ gcc -o wshtml wshtml.cConverting WordStar files
The program makes it easy to convert legacy WordStar files into more portable HTML documents:
$ ./wshtml sample.ws > sample.htmlRunning the wshtml program converts my sample WordStar document into HTML, which I can view in my browser:

While this program converts the inline formatting via the control codes, it does not recognize the dot commands as anything other than normal text; any dot commands will be included verbatim in the output, just like body text. If you are interested in converting files that also use dot commands for document-level formatting, you can use this program as a starting point.
More Stories
Connect to a Windows drive from Linux
Here’s how I connected my Linux system to a Windows AD fileshare.
Reading a whole file at once
Two methods to load a data file into memory. Use mmap on Linux sysetms.
Old-school programming with Turbo C
Explore retroprogramming on FreeDOS with this popular freeware IDE.
Calculate pi by counting pixels
This is a very simple way to measure pi, but it was a fun exercise and I wanted to share it.
Perl and Raku Conference will be held June 27-29, 2025 in Greenville, SC, USA
David Both to be the keynote speaker The Perl and Raku Conference for 2025 is coming up June 27-29, 2025,...
Using AI to translate code
I was impressed that AI did so well translating from an old language like FORTRAN 77 into a more modern language like C.